
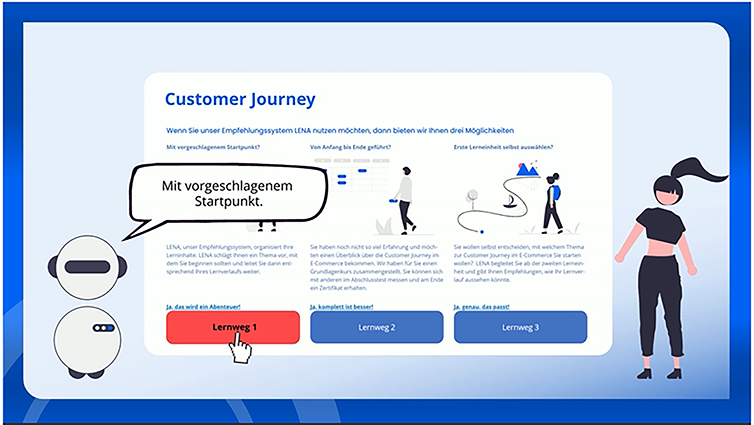
Im Projekt ELe-Com haben wir es uns zur Aufgabe gemacht, ein System mit mehreren Lernmöglichkeiten zu entwickeln, das das Lernen für die Nutzer:innen mit unterschiedlichen Lernbedürfnissen und Präferenzen attraktiver und leichter macht. Das entwickelte Lernangebot wird in Form von Micro-Lerneinheiten über die Lernplattform ILIAS zur Verfügung gestellt. Die Nutzer:innen können sich freiwillig entscheiden, ob sie von unseren Assistenzsystemen komplett, teilweise oder gar nicht geführt werden. Außerdem besteht die Möglichkeit, aus drei Lernformaten auszuwählen – Lesen, Hören oder Sehen. Die Nutzer:innen, die unseren Lernnavigator LENA nutzen möchten, geben zu Beginn ihre Lernpräferenzen über eine kurze Abfrage an und legen mit dem Lernen los. Ab diesem Zeitpunkt kommt das intelligente KI-basierte Empfehlungssystem – EMIL zur Unterstützung. EMIL sammelt und wertet die Daten zu Lernaktivitäten aus, um den Lernenden Empfehlungen auszusprechen, damit sie schneller und effektiver zum Lernziel kommen. Im Weiteren möchten wir Ihnen kurz darstellen, welche Anforderung wir bezüglich der Datenerfassung hatten und welche Lösung dafür eingesetzt wird.
Die Anforderung: Daten
ILIAS ist hinsichtlich der Erfassung von Lernaktivitäten beschränkt. ILIAS weiß grundsätzlich, ob ein Objekt noch offen, in Bearbeitung oder abgeschlossen ist. Oder ob eine Datei angeklickt wurde oder bis zu welcher Stelle in einer Lernsequenz Lernende die Inhalte bearbeitet haben. ILIAS kann außerdem Lernfortschritte aus SCORM-Dateien erfassen.
Das KI-basierte Entscheidungsmodul EMIL benötigt jedoch mehr Daten, um gute Empfehlungen für adaptives Lernen auszusprechen. Mehr als ILIAS im Standard zur Verfügung stellt.
Für gute Empfehlungen ist es z.B. gut zu wissen, mit welchen Lernmedien gelernt wurde. Ob bspw. ein Video angeklickt wurde. Ob es zu Ende geschaut wurde oder an welcher Stelle es abgebrochen wurde. Daraus ließe sich ableiten, ob eine angegebene Präferenz tatsächlich beibehalten wird.
Ober auch, welche Antworten in einem Quiz gegeben wurden. Wieviel falsche, wieviel richtige und bei wieviel Durchläufen? Daraus könnte die KI das bisherige Wissen und den aktuellen thematischen Bedarf besser ableiten.
Die Lösung: xAPI
Damit EMIL ausreichend Daten für präzise Empfehlungen bekommt, setzen wir im Projekt xAPI ein.
xAPI ist ein Datenmodell, das im Prinzip jeder aus den Statusmeldungen von Sozialen Netzwerken kennt: Ein Mensch | hat angeschaut | ein Video. Jemand | hat ein Like hinterlassen | zu einem bestimmten Bild. Subjekt, Prädikat und Objekt.
Dieses grundsätzliche Datenmodell lässt sich um weitere Informationen ergänzen: Actor (wer hat gehandelt) > Verb (was wurde getan) > Object (wo fand die Handlung statt) > Result (mit welchem Ergebnis) > Context (erweiterte Informationen) > Timestamp (wann wurde am Objekt gearbeitet).
Die Sache ist nur: ILIAS 7 kann kein xAPI.
Die Umsetzung: Plugin für ILIAS
Um diese Lücke zu schließen, kooperierten wir mit einem weiteren INVITE Projekt „VerDatAs“ (https://www.verdatas.de/) und setzen das Plugin „Events2Lrs“ ein, das vom Projektpartner internet-lehrer gmbh (https://internetlehrer-gmbh.de) entwickelt wurde.
- Das Plugin definiert, zu welchem Learning Record Store (LRS) die xAPI-Daten gesendet werden. Der Learning Record Store spielt eine wichtige Rolle, da hier alle erhobenen xAPI-Statements gesammelt werden, und an die KI zur Verarbeitung weitergeleitet werden können.
- Das Plugin erlaubt mit je einem Klick zu definieren, welche Verben aus den H5P-Elementen, aus denen die Micro Lerneinheiten bestehen, an den LRS weitergeleitet werden – z.B. attempted, interacted oder completed.
- Außerdem integriert das Plugin ILIAS-Events, die als xAPI-Statements an den LRS weitergeleitet werden – was ILIAS im Standard nicht kann. Das betrifft Lernfortschritte von ILIAS-Objekten und die Anzahl der Objekt-Aufrufe allgemein, und Events rund um ILIAS-Tests im Besonderen.
Damit bekommen wir erstmals ein feingranuliertes Bild davon, was in ILIAS und den H5P-Elementen passiert. Und so funktioniert das Plugin im Zusammenspiel mit den anderen Systemelementen:
- Ein Lernobjekt in ILIAS, das H5P-Elemente beinhaltet, wird von einem angemeldeten Benutzer mit dessen Profildaten und Präferenzen aufgerufen.
- Die Aktivität erzeugt xAPI-Statements. Diese Statements werden vom Plugin erfasst, und im nächsten Schritt an den LRS weitergeleitet – zusammen mit den Angaben über den jeweiligen Lernenden und dessen Präferenzen (xAPI-Datenmodell: „Context“).
- Der Learning Record Store informiert ILIAS über die erfassten Lernstände.
Diese erfassten xAPI-Statements werden vom LRS während dieser Vorgänge parallel an das Entscheidungsmodul EMIL zur Verarbeitung weitergeleitet. Was genau dort passiert, war z. B. Gegenstand des vorherigen News Artikels zum Thema „Was macht eigentlich EMIL? – Status Quo des Entscheidungsmoduls“.


 In den letzten Monaten haben wir uns intensiv mit der Entwicklung unseres KI-basierten Entscheidungsmoduls EMIL beschäftigt. Die Entwicklung basiert auf dem neuesten Stand der Technik von Fully Connected Neural Networks, zu Deutsch etwa „vollständig verbundene neuronale Netzwerke“. Ziel des zu entwickelnden KI-Modells ist es, Empfehlungen zu individuellen Lernpfaden und Lernangeboten auf der Grundlage der Bedürfnisse von Nutzer:innen zu geben.
In den letzten Monaten haben wir uns intensiv mit der Entwicklung unseres KI-basierten Entscheidungsmoduls EMIL beschäftigt. Die Entwicklung basiert auf dem neuesten Stand der Technik von Fully Connected Neural Networks, zu Deutsch etwa „vollständig verbundene neuronale Netzwerke“. Ziel des zu entwickelnden KI-Modells ist es, Empfehlungen zu individuellen Lernpfaden und Lernangeboten auf der Grundlage der Bedürfnisse von Nutzer:innen zu geben.